Class Activation Mapping
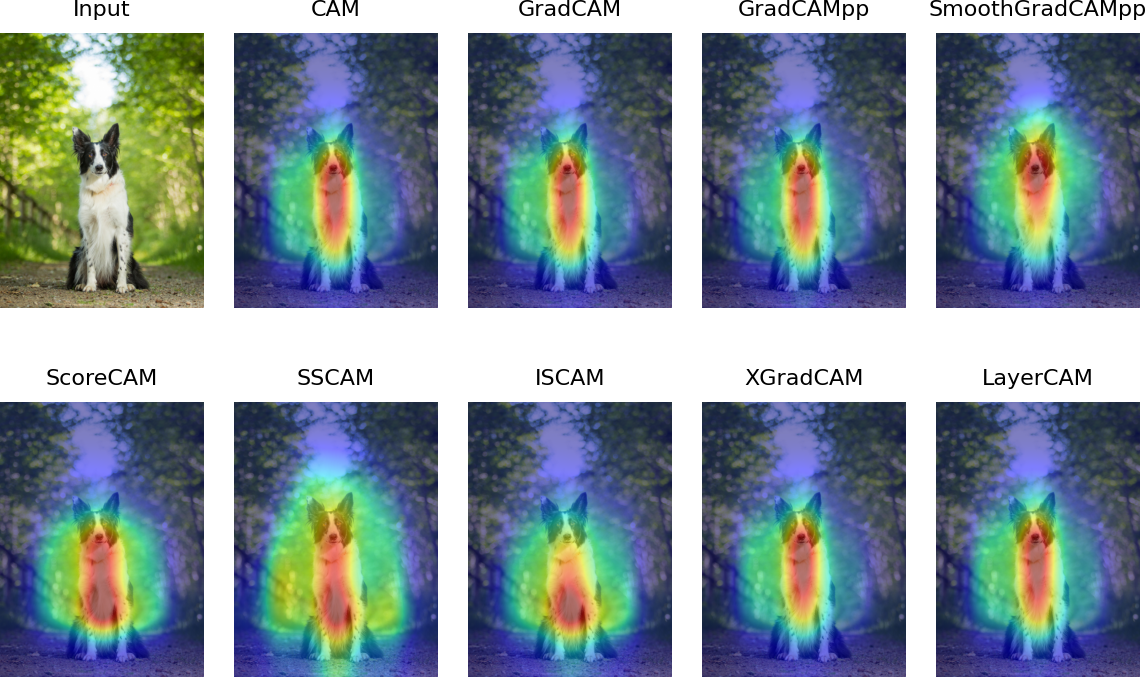

By simply upsampling the class activation map to the size of the input image, we can identify the image regions most relevant to the particular category
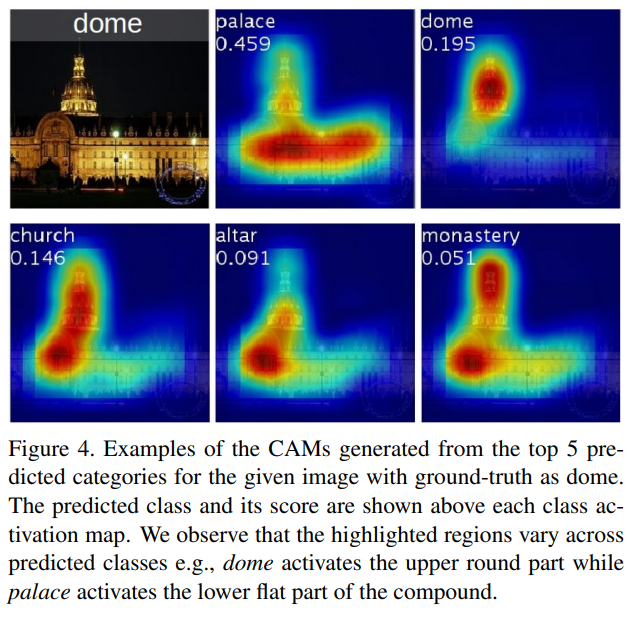
CAM
We perform global average pooling on the convolutional feature maps and use those as features for a fully-connected layer that produces the desired output (categorical or otherwise). Given this simple connectivity structure, we can identify the importance of the image regions by projecting back the weights of the output layer on to the convolutional feature maps, a technique we call class activation mapping.
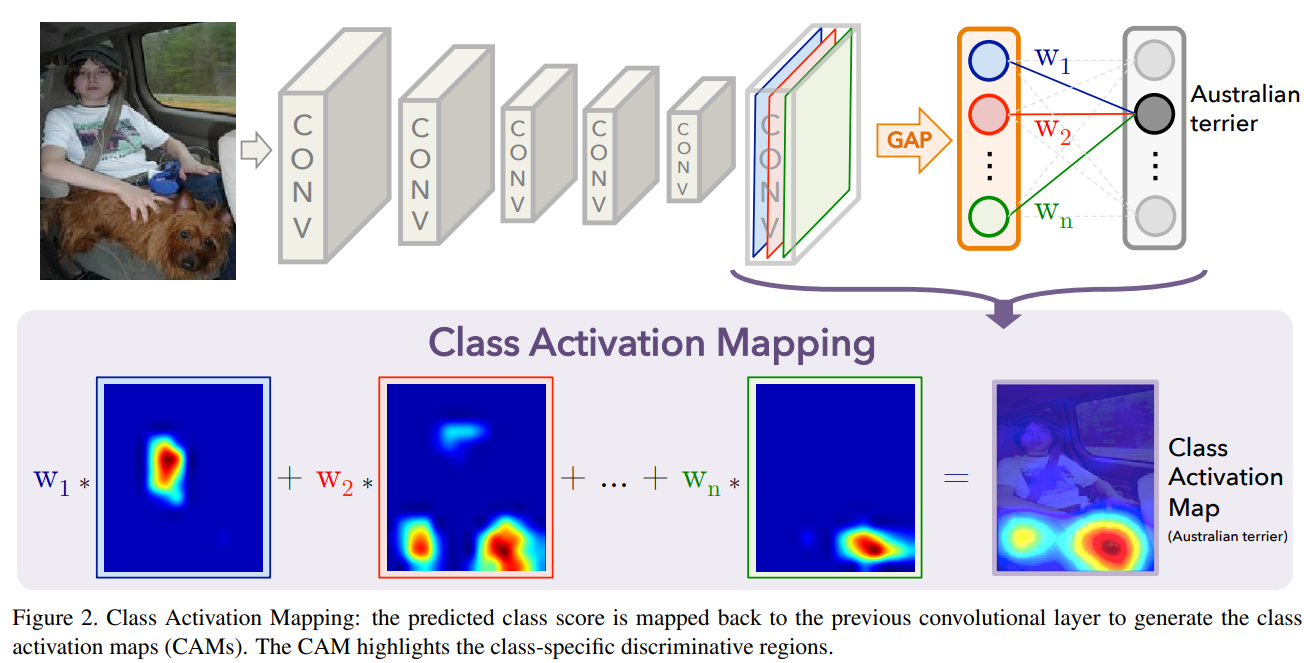
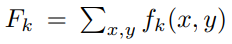
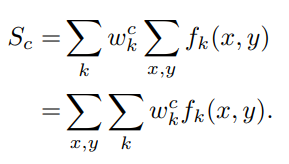
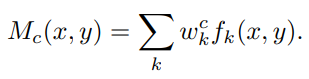
By simply up-sampling the class activation map to the size of the input image, we can identify the image regions most relevant to the particular category
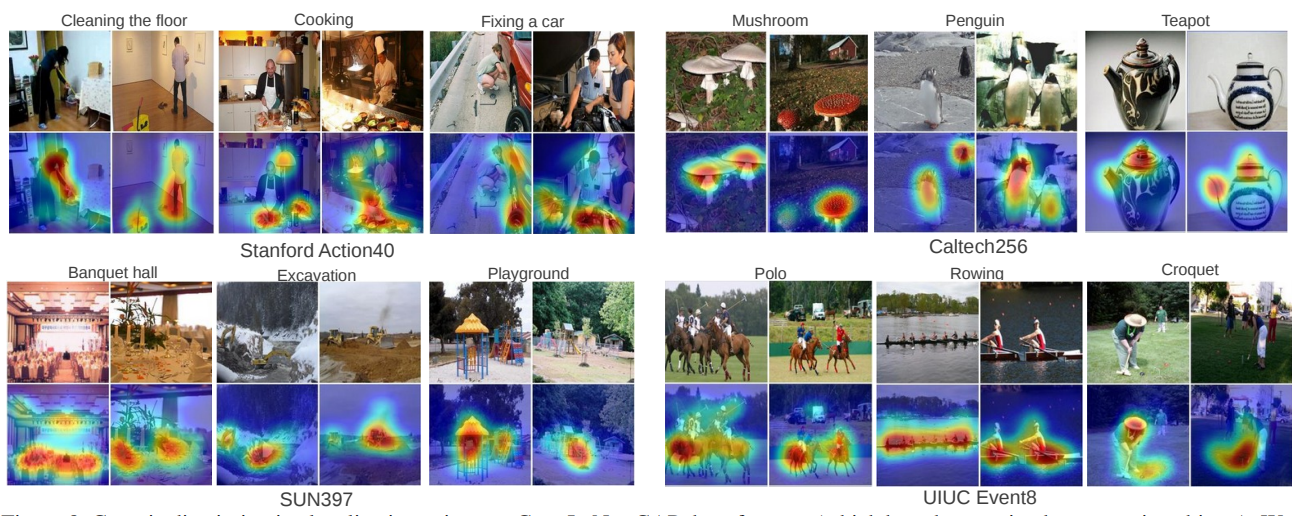
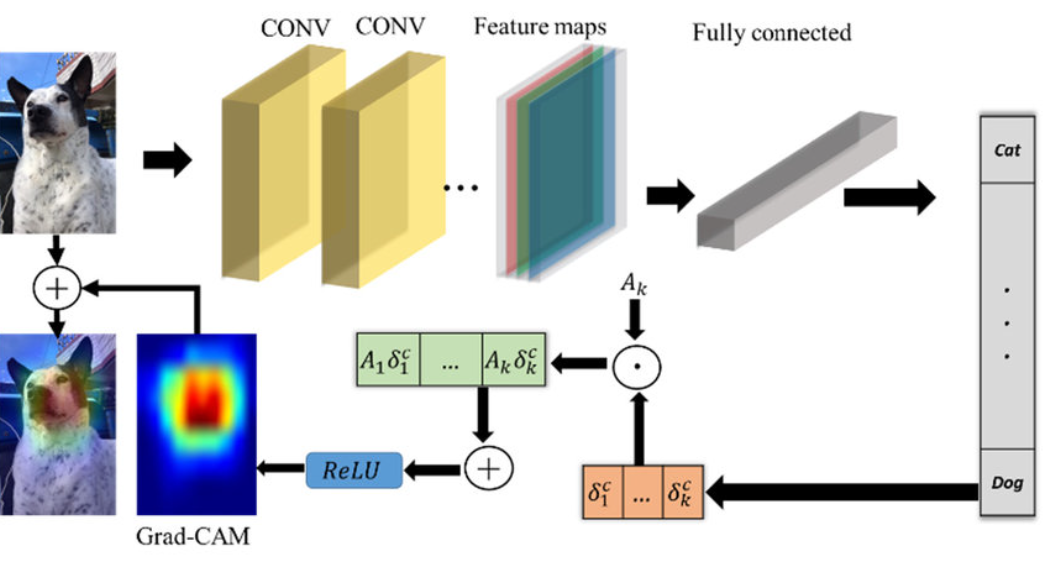
Grad-CAM
Why does interpretability matter? - Transparency
- First, when AI is significantly weaker than humans and not yet reliably deployable (e.g. visual question answering), the goal of transparency and explanations is to identify the failure modes, thereby helping researchers focus their efforts on the most fruitful research directions.
- Second, when AI is on par with humans and reliably deployable (e.g., image classification trained on sufficient data), the goal is to establish appropriate trust and confidence in users.
- Third, when AI is significantly stronger than humans (e.g. chess or Go), the goal of explanations is in machine teaching – i.e., a machine teaching a human about how to make better decisions.
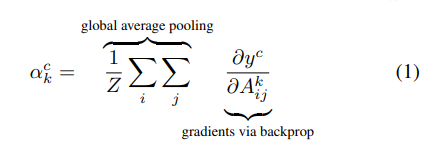
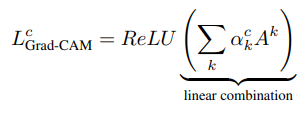
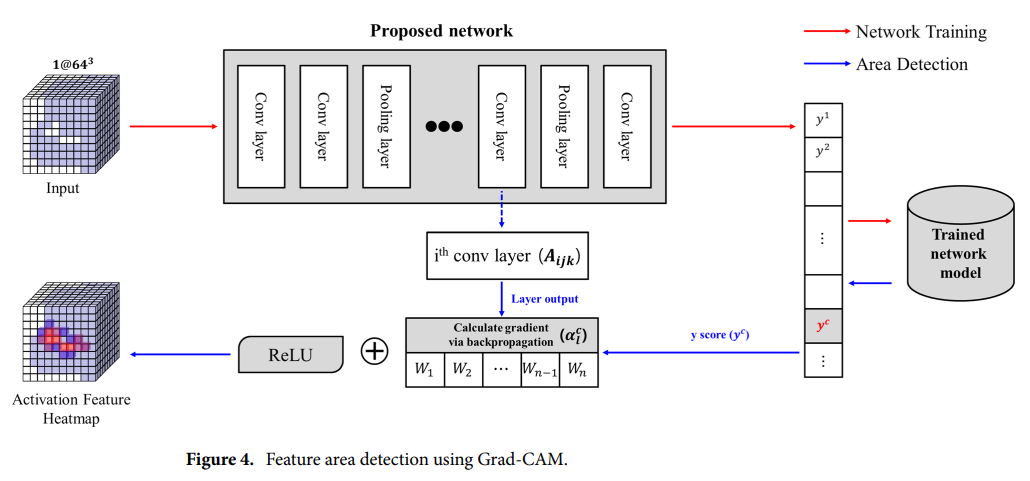
3D Conv & Grad-CAM

References
Paper
- Learning Deep Features for Discriminative Localization - CAM
- Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization - Grad-CAM
- 3D convolutional neural network for machining feature recognition with gradient‑based visual explanations from 3D CAD models - 3D ConvNet